
前言
Ceph早期的单机对象存储引擎是FileStore,为了维护数据的一致性,写入之前数据会先写Journal,然后再写到文件系统,会有一倍的写放大,而同时现在的文件系统一般都是日志型文件系统(ext系列、xfs),文件系统本身为了数据的一致性,也会写Journal,此时便相当于维护了两份Journal;另外FileStore是针对HDD的,并没有对SSD作优化,随着SSD的普及,针对SSD优化的单机对象存储也被提上了日程,BlueStore便由此应运而出。
BlueStore最早在Jewel版本中引入,用于在SSD上替代传统的FileStore。作为新一代的高性能对象存储后端,BlueStore在设计中便充分考虑了对SSD以及NVME的适配。针对FileStore的缺陷,BlueStore选择绕过文件系统,直接接管裸设备,直接进行对象数据IO操作,同时元数据存放在RocksDB,大大缩短了整个对象存储的IO路径。BlueStore可以理解为一个支持ACID事物型的本地日志文件系统。
目录
设计理念
存储系统中,数据的可靠性是至关重要的。所有的读操作都是同步的,也就是除非命中缓存,否则必须从磁盘上读到指定的数据才能返回。但是写操作则不一样,一般为了性能考虑,所有写操作都会先写内存缓存Page-Cache便返回客户端成功,然后由文件系统批量刷盘。但是内存是易失性存储介质,掉电后数据便会丢失,所以为了数据可靠性,我们不能这么做。
一种可行的替代方案便是将数据先写入性能更好的非易失性存储介质(SSD、NVME等)充当的中间设备,然后再将数据写入内存缓存,便可以直接返回客户端成功,等到数据写入到普通磁盘的时候再释放中间设备对应的空间。写入中间设备的过程我们称为写日志Journal。如果写Journal的过程失败了,那么直接返回失败即可,如果刷磁盘失败了,那么我们可以基于Journal来重放相应的数据,并不会影响系统的正确性。但是由于引入了Journal,所以存在双写,造成了写放大。在生产环境一般用SSD或者NVME做Journal,HDD做普通大容量存储。
除了数据可靠性,数据一致性也是重中之重。涉及数据修改的所有操作,要么完全完成,要么没有变化,而不能是介于两者之间的中间状态,也就是所有的修改都要符合事物的ACID语义,同时符合上述语义的存储系统我们称之为事务型存储系统。
BlueStore便是一个事务型的本地日志文件系统。因为面向下一代全闪存阵列的设计,所以BlueStore在保证数据可靠性和一致性的前提下,需要尽可能的减小日志系统中双写带来的影响。全闪存阵列的存储介质的主要开销不再是磁盘寻址时间,而是数据传输时间。因此当一次写入的数据量超过一定规模后,写入Journal盘(SSD)的延时和直接写入数据盘(SSD)的延迟不再有明显优势,所以Journal的存在性便大大减弱了。但是要保证OverWrite(覆盖写)的数据一致性,又不得不借助于Journal,所以针对Journal设计的考量便变得尤为重要了。
一个可行的方式是使用增量日志。针对大范围的覆盖写,只在其前后非磁盘块大小对齐的部分使用Journal,即RMW,其他部分直接重定向写COW即可。
BlockSize:磁盘IO操作的最小单元(原子操作)。HDD为512B,SSD为4K。即读写的数据就算少于BlockSize,磁盘IO的大小也是BlockSize,是原子操作,要么写入成功,要么写入失败,即使掉电不会存在部分写入的情况。
RWM(Read-Modify-Write):指当覆盖写发生时,如果本次改写的内容不足一个BlockSize,那么需要先将对应的块读上来,然后再内存中将原内容和待修改内容合并Merge,最后将新的块写到原来的位置。但是RMW也带来了两个问题:一是需要额外的读开销;二是RMW不是原子操作,如果磁盘中途掉电,会有数据损坏的风险。为此我们需要引入Journal,先将待更新数据写入Journal,然后再更新数据,最后再删除Journal对应的空间。
COW(Copy-On-Write):指当覆盖写发生时,不是更新磁盘对应位置已有的内容,而是新分配一块空间,写入本次更新的内容,然后更新对应的地址指针,最后释放原有数据对应的磁盘空间。理论上COW可以解决RMW的两个问题,但是也带来了其他的问题:一是COW机制破坏了数据在磁盘分布的物理连续性。经过多次COW后,读数据的顺序读将会便会随机读。二是针对小于块大小的覆盖写采用COW会得不偿失。是因为:一是将新的内容写入新的块后,原有的块仍然保留部分有效内容,不能释放无效空间,而且再次读的时候需要将两个块读出来做Merge操作,才能返回最终需要的数据,将大大影响读性能。二是存储系统一般元数据越多,功能越丰富,元数据越少,功能越简单。而且任何操作必然涉及元数据,所以元数据是系统中的热点数据。COW涉及空间重分配和地址重定向,将会引入更多的元数据,进而导致系统元数据无法全部缓存在内存里面,性能会大打折扣。
整体架构
基于以上设计理念,BlueStore的写策略综合运用了COW和RMW策略。非覆盖写直接分配空间写入即可;块大小对齐的覆盖写采用COW策略;小于块大小的覆盖写采用RMW策略。
整体架构设计如下图:
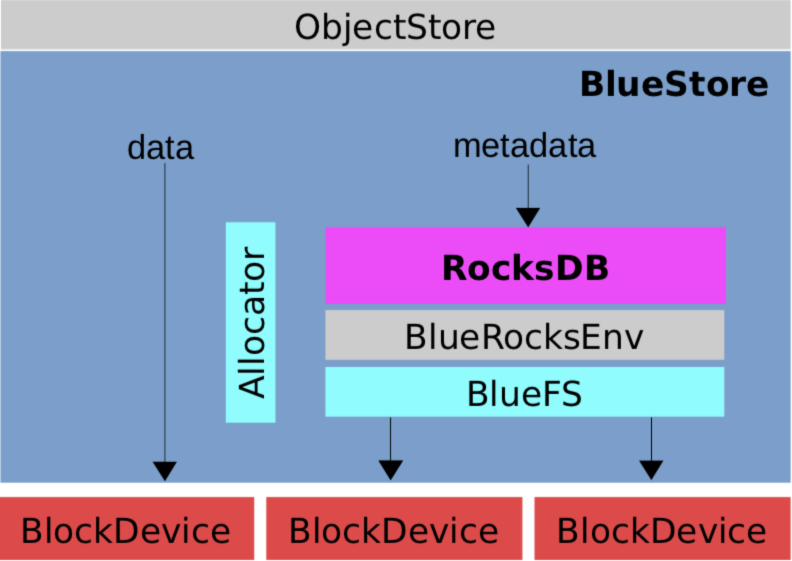
核心模块
- BlockDevice:物理块设备,使用
Libaio操作裸设备,AsyncIO。 - RocksDB:存储
WAL、对象元数据、对象扩展属性Omap、磁盘分配器元数据。 - BlueRocksEnv:抛弃了传统文件系统,封装RocksDB文件操作的接口。
- BlueFS:小型的
Append文件系统,实现了RocksDB::Env接口,给RocksDB用。 - Allocator:磁盘分配器,负责高效的分配磁盘空间。
BlueFS
RocksDB是基于本地文件系统的,但是文件系统的许多功能对于RocksDB不是必须的,所以为了提升RocksDB的性能,需要对本地文件系统进行裁剪。最直接的办法便是为RocksDB量身定制一套本地文件系统,BlueFS便应运而生。
BlueFS是个简易的用户态日志型文件系统,恰到好处的实现了RocksDB::Env所有接口。根据设计理念这一章节,我们知道引入Journal是为了进行写加速,WAL对于提升RocksDB的性能至关重要,所以BlueFS在设计上支持把.log和.sst分开存储,.log使用速度更快的存储介质(NVME等)。
在引入BlueFS后,BlueStore将所有存储空间从逻辑上分了3个层次:
- 慢速空间(Block):存储对象数据,可以使用
HDD,由BlueStore管理。 - 高速空间(DB):存储
RocksDB的sst文件,可以使用SSD,由BlueFS管理。 - 超高速空间(WAL):存储
RocksDB的log文件,可以使用NVME,由BlueFS管理。
Alloactor
BlueStore的磁盘分配器,负责高效的分配磁盘空间。目前支持Stupid和Bitmap两种磁盘分配器。都是仅仅在内存中分配,并不做持久化。
FreeListManager
负责管理空闲空间列表。目前支持Extent和Bitmap两种,由于Extent开销大,新版中已经移除,只剩Bitmap。空闲的空间列表会持久化在RocksDB中,为了保证元数据和数据写入的一致性,BitmapFreeListmanager会由使用者调用,会将对象元数据和分配结果通过RocksDB的WriteBatch接口原子写入。
Cache
BlueStore抛弃了文件系统,直接管理裸设备,那么便用不了文件系统的Cache机制,需要自己实现元数据和数据的Cache,缓存系统的性能直接影响到了BlueStore的性能。
BlueStore有两种Cache算法:LRU和2Q。元数据使用LRUCache策略,数据使用2QCache策略。
IO流程
读流程
处理读请求会先从RocksDB找到对应的磁盘空间,然后通过BlockDevice读出数据。
写流程
处理写请求时会进入事物的状态机,简单流程就是先写数据,然后再原子的写入对象元数据和分配结果元数据。写入数据如果是对齐写入,则最终会调用do_write_big;如果是非对齐写,最终会调用do_write_small。
具体的IO流程会在之后的篇幅分析。
参考资源
转载请注明:史明亚的博客 » BlueStore源码分析之架构设计




