
前言
前面介绍了BlueStore的BitMap分配器,我们知道新版本的Bitmap分配器的优势在于使用连续的内存空间从而尽可能更多的命中CPU Cache以提高分配器性能。在这里我们了解一下基于区间树的Stupid分配器(类似于Linux Buddy内存管理算法),并对比分析一下其优劣。
目录
伙伴算法
Linux内存管理算法为了能够快速响应请求,尽可能的提高内存利用率同时减少外部内存碎片,引入了伙伴系统算法Buddy-System。该算法将所有的空闲页分组为11个链表,每个链表分别包含1、2、4、8、16、32、64、128、256、512、1024个连续的页框块,每个页框块的第一个内存页的物理地址是该块大小的整数倍。伙伴的特点是:两个块大小相同、两个块地址连续、第一块的第一个页框的物理地址是两个块总大小的整数倍(同属于一个大块,第1块和第2块是伙伴,第3块和第4块是伙伴,但是第2块和第3块不是伙伴)。具体内存分配和内存释放可自行Google。
优点:
- 较好的解决外部碎片问题,不能完全解决。
- 针对大内存分配设计,可以快速的分配连续的内存。
缺点:
- 合并的要求过于严格,只能是满足伙伴关系的块才可以合并。
- 一块连续的内存中仅有一个页面被占用,就导致整个内存不具备合并的条件。
- 算法页面连续性差,DMA申请大块连续物理内存空间可能失败,此时需要
CMA(Contiguous Memory Allocator, 连续内存分配器)。 - 浪费空间,可以通过slab、kmem_cache等解决。
数据结构
Stupid分配器使用了区间树组织数据结构,高效管理Extent(offset, length)。
class StupidAllocator : public Allocator {
CephContext* cct;
// 分配空间用的互斥锁
std::mutex lock;
// 空闲空间总大小
int64_t num_free;
// 最后一次分配空间的位置
uint64_t last_alloc;
// 区间树数组,初始化的时候,free数组的长度为10,即有十颗区间树
std::vector<interval_set_t> free;
// extent: offset, length
typedef mempool::bluestore_alloc::pool_allocator<
pair<const uint64_t, uint64_t>>
allocator_t;
// 有序的 btree map,按顺存放extent。
typedef btree::btree_map<uint64_t, uint64_t, std::less<uint64_t>,
allocator_t> interval_set_map_t;
// 区间树,主要的操作有 insert、erase等。
typedef interval_set<uint64_t, interval_set_map_t> interval_set_t;
};
每颗区间树的下标为index(0-9),index(1-9)表示的空间大小为:[2^(index-1) * bdev_block_size, 2^(index) * bdev_block_size),
- free[0]: [0, 4k)
- free[1]: [4k, 8k)
- free[2]: [8k, 16k)
- free[3]: [16k, 32k)
- free[4]: [32k, 64k)
- free[5]: [64k, 128k)
- free[6]: [128k, 256k)
- free[7]: [256k, 512k)
- free[8]: [512k, 1024k)
- free[9]: [1024k, 2048k)
初始化
初始化Stupid分配器后,调用者会向Allocator中加入或者删除空闲空间。
// 增加空闲空间
void StupidAllocator::init_add_free(uint64_t offset, uint64_t length) {
std::lock_guard<std::mutex> l(lock);
// 向 free 中插入空闲空间
_insert_free(offset, length);
// 更新空闲空间大小
num_free += length;
}
// 删除空闲空间
void StupidAllocator::init_rm_free(uint64_t offset, uint64_t length)
{
std::lock_guard<std::mutex> l(lock);
interval_set_t rm;
rm.insert(offset, length);
for (unsigned i = 0; i < free.size() && !rm.empty(); ++i) {
interval_set_t overlap;
overlap.intersection_of(rm, free[i]);
// 删除相应空间
if (!overlap.empty()) {
free[i].subtract(overlap);
rm.subtract(overlap);
}
}
num_free -= length; // 更新可用空间
}
插入删除
区间树实现代码:
https://github.com/ceph/ceph/blob/master/src/include/interval_set.h
insert函数代码:
https://github.com/ceph/ceph/blob/master/src/include/interval_set.h#L445
erase函数代码:
https://github.com/ceph/ceph/blob/master/src/include/interval_set.h#L516
最核心的实现是向区间树中插入以及删除区间,代码如下:
区间树插入Extent
// 根据区间的长度,选取将要存放的区间树,长度越大,bin值越大。
unsigned StupidAllocator::_choose_bin(uint64_t orig_len)
{
uint64_t len = orig_len / cct->_conf->bdev_block_size;
// cbits = (sizeof(v) * 8) - __builtin_clzll(v)
// __builtin_clzll 返回前置的0的个数
// cbits 结果是最高位1的下标(从0开始),len越大,值越大
int bin = std::min(int)cbits(len), (int)free.size() - 1);
return bin;
}
void StupidAllocator::_insert_free(uint64_t off, uint64_t len)
{
// 计算该段空闲空间属于哪个区间树
unsigned bin = _choose_bin(len);
while (true) {
// 空闲空间插入区间树
free[bin].insert(off, len, &off, &len);
unsigned newbin = _choose_bin(len);
if (newbin == bin)
break;
// 插入数据后,可能合并区间,导致区间长度增大,可能要调整bin,此时需要将旧的删除,然后插入新的bin
// 区间合并有两种情况:一是合并在原有区间前面;而是合并在原有区间后面。
free[bin].erase(off, len);
bin = newbin;
}
}
回顾第一节伙伴算法,两种合并的方式是有区别的:
- 伙伴算法要求比较严格,参考第一节。
- Stupid Extent合并比较松散,只要满足两个Extent空间连续就可以。
区间树删除Extent
区间树删除Extent比较简单,在原来Extent删除传入的Extent,然后计算最终Extent是否落入其他区间树,如果落入则从此区间树删除,加入新的区间树。
空间分配
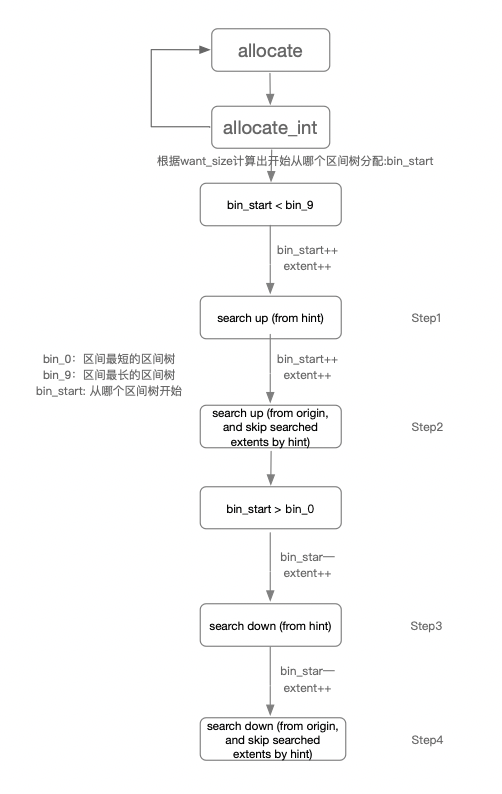
空间分配的函数定义如下:
allocate(uint64_t want_size, uint64_t alloc_unit,
uint64_t max_alloc_size, int64_t hint,PExtentVector* extents);
allocate_int(uint64_t want_size, uint64_t alloc_unit, int64_t hint,
uint64_t* offset, uint32_t* length)
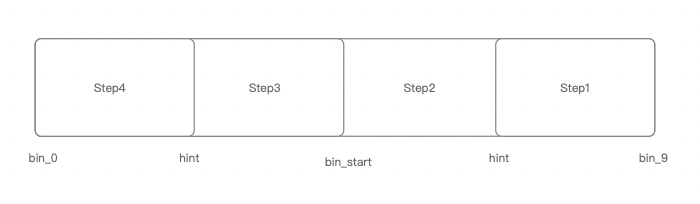
其中hint是一个很重要的参数,表示分配的起始地址要尽量大于hint的值。
核心流程为4个2层for循环大致为:优先从hint地址依次向高级区间树开始分配长度大于等于want_size的连续空间,如果没有,则优先从hint地址依次向低级区间树开始分配长度大于等于alloc_unit的连续空间(长度会大于alloc_unit)。
简单的空间分配图如下:
详细的空间分配流程图如下:
空间回收
空间释放的函数定义如下:
release(const interval_set<uint64_t> &release_set)
流程很简单,先加锁,然后循环调用_insert_free插入到对应区间树里面,会涉及到相邻空闲空间的合并,但是会导致分配空间碎片的问题。
优劣分析
CPU Cache
Stupid底层使用BtreeMap来存储一系列的Extent,内存不一定是连续的,同时在分配空间遍历区间树时,虽然区间树里面的Extent是有序的,但是由于内存不一定是连续或者相邻的两个Extent内存跨度可能很大,都会导致CPU-Cache预读不到下一个Extent,从而不能很好的利用CPU-Cache。
Bitmap分配器在BlueStore初始化时就初始化好了3层,而且大小是固定的,同时分配空间是依次顺序分配,从而可以充分的利用CPU-Cache的功能。从而提高分配器的性能。
伪空间碎片
基于Extent的Stupid分配器存在伪空间碎片(物理空间是连续的,但是分配器中却不连续)问题:
一个24K的连续空间,经过6次4K分配和乱序的6次4K释放后,可能会变成8K + 4K + 8K + 4K四块空间。
其中两个4K的区间由于和周边块大小一样,所以落到不同的区间树中,导致很难被合并,24K的连续空间变成了四块不连续空间。
Bitmap分配器由于初始化时就分配好了3层所有内存,而且3层都是有序的的同时分配空间是顺序遍历的,在释放空间的时候设置相应位就可以,不影响连续性,所以不存在这个问题。
据Bitmap作者的性能对比实验来看,Bitmap分配器要好于Stupid,等Bitmap稳定后,可以设置BlueStore的默认分配器为Bitmap。
参考资源
转载请注明:史明亚的博客 » BlueStore源码分析之Stupid分配器




