
前言
分布式一致性是分布式系统中最基本的问题,用来保证分布式系统的高可靠。业界也有很多分布式一致性复制协议:Paxos、Zab、Viewstamped Replication、Raft等。Raft相比于其他共识算法简化了协议中的状态以及交互,更加清晰也更加容易理解实现。
这篇文章作为Raft的学习、思考、整理,各种查资料前前后后花了3天时间,包含以下内容,老铁手动点个👍吧。:)
Leader Election、Log Replication、Log Recovery、Log Compaction、Membership Change、Safety
Pre-Vote、Transfer Leader、Network Partition、SetPeer、Noop、MultiRaft、Learner
Batch、PipeLine、Parallel、Out-of-Order、Asynchronous、ReadIndex、Lease Read、Follower Read、Double Write-Store
目录
Raft概述
Raft节点有3种角色:
- Leader:处理客户端读写、服饰Log给Follower等。
- Candidate:竞选新的Leader(由Follower超时转换得来)。
- Follower:不发送任何请求,完全被动响应Leader、Candidate的RPC。
Raft信息有3种RPC:
- RequestVote RPC:由Candidate发出,用于发送投票请求。
- AppendEntries (Heartbeat) RPC:由Leader发出,用于Leader向Followers复制日志条目,也会用作Heartbea(日志条目为空即为 Heartbeat)。
- InstallSnapshot RPC:由Leader发出,用于快照传输,虽然多数情况都是每个服务器独立创建快照,但是Leader有时候必须发送快照给一些落后太多的Follower,这通常发生在Leader已经丢弃了下一条要发给该Follower的日志条目(Log Compaction 时清除掉了的情况)。
Leader Election
Raft将时间划分为一个个的任期(Term),TermID单调递增,每个Term最多只有一个Leader。
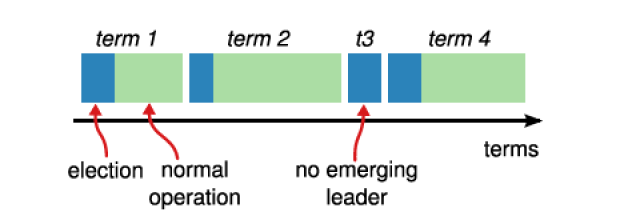
Candidate先将本地的currentTerm++,然后向其他节点发送RequestVote请求,其他节点根据本地数据版本、长度和之前选主的结果判断应答成功与否。具体处理规则如下:
- 如果Time.Now() – lastLeaderUpdateTimestamp < electionTimeout,忽略请求。
- 如果req.term < currentTerm,忽略请求。
- 如果req.term > currentTerm,设置currentTerm = req.term,如果是Leader和Candidate转为Follower。
- 如果req.term == currentTerm,并且本地voteFor记录为空或者是与vote请求中term和CandidateId一致,req.lastLogIndex > lastLogIndex,即Candidate数据新于本地则同意选主请求。
- 如果req.term == currentTerm,如果本地voteFor记录非空或者是与vote请求中term一致CandidateId不一致,则拒绝选主请求。
- 如果req.term == currentTerm,如果lastLogTerm > req.lastLogTerm,本地最后一条Log的Term大于请求中的lastLogTerm,说明candidate上数据比本地旧,拒绝选主请求。
currentTerm只是用于忽略老的Term的vote请求,或者提升自己的currentTerm,并不参与Log新旧的决策。 Log新旧的比较,是基于lastLogTerm和lastLogIndex进行比较,而不是基于currentTerm和lastLogIndex进行比较。
关于选举有两个很重要的随机超时时间:心跳超时、选举超时。
- 心跳超时:Leader周期性的向Follower发送心跳(0.5ms – 20ms),如果Follower在选举超时时间内没有收到心跳,则触发选举。
- 选举超时:如果存在两个或者多个节点选主,都没有拿到大多数节点的应答,需要重新选举,Raft引入随机的选举超时时间(150ms – 300ms),避免选主活锁。
心跳超时要小于选举超时一个量级,Leader才能够发送稳定的心跳消息来阻止Follower开始进入选举状态。可以设置:心跳超时=peers max RTT(round-trip time),选举超时=10 * 心跳超时。
Log Replication
大致流程是:更新操作通过Leader写入Log,复制到多数节点,变为Committed,再Apply业务状态机。
Leader首先要把这个指令追加到log中形成一个新的entry,然后通过AppendEntries RPCs并行的把该entry发给其他servers,其他server如果发现没问题,复制成功后会给Leader一个表示成功的ACK,Leader收到大多数ACK后Apply该日志,返回客户端执行结果。如果Followers crash或者丢包,Leader会不断重试AppendEntries RPC。
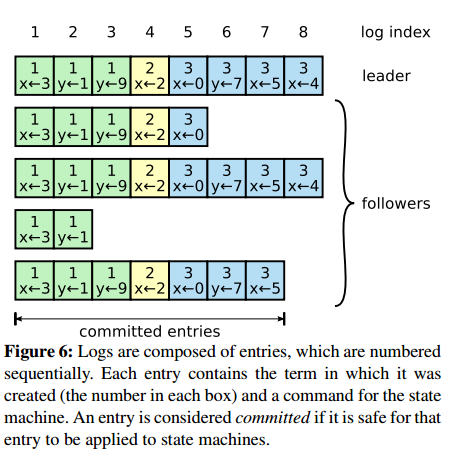
- Raft要求所有的日志不允许出现空洞。
- Raft的日志都是顺序提交的,不允许乱序提交。
- Leader不会覆盖和删除自己的日志,只会Append。
- Follower可能会截断自己的日志。存在脏数据的情况。
- Committed的日志最终肯定会被Apply。
- Snapshot中的数据一定是Applied,那么肯定是Committed的。
- commitIndex、lastApplied不会被所有节点持久化。
- Leader通过提交一条Noop日志来确定commitIndex。
- 每个节点重启之后,先加载上一个Snapshot,再加入RAFT复制组
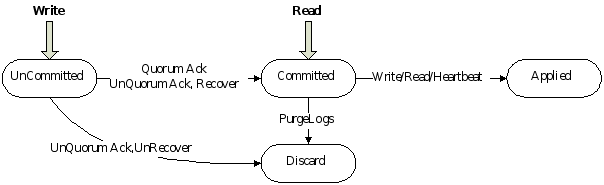
每个log entry都存储着一条用于状态机的指令,同时保存着从Leader收到该entry时的Term,此外还有index指明自己在Log中的位置。可以被Apply的entry叫做committed,一个log entry一旦复制给了大多数节点就成为committed,committed的log最终肯定会被Apply。
如果当前待提交entry之前有未提交的entry,即使是以前过时的leader创建的,只要满足已存储在大多数节点上就一次性按顺序都提交。
Log Recovery
Log Recovery分为currentTerm修复和prevTerm修复。Log Recovery就是要保证一定已经Committed的数据不会丢失,未Committed的数据转变为Committed,但不会因为修复过程中断又重启而影响节点之间一致性。
currentTerm修复主要是解决某些Follower节点重启加入集群,或者是新增Follower节点加入集群,Leader需要向Follower节点传输漏掉的Log Entry,如果Follower需要的Log Entry已经在Leader上Log Compaction清除掉了,Leader需要将上一个Snapshot和其后的Log Entry传输给Follower节点。Leader-Alive模式下,只要Leader将某一条Log Entry复制到多数节点上,Log Entry就转变为Committed。
prevTerm修复主要是在保证Leader切换前后数据的一致性。通过上面RAFT的选主可以看出,每次选举出来的Leader一定包含已经committed的数据(抽屉原理,选举出来的Leader是多数中数据最新的,一定包含已经在多数节点上commit的数据),新的Leader将会覆盖其他节点上不一致的数据。虽然新选举出来的Leader一定包括上一个Term的Leader已经Committed的Log Entry,但是可能也包含上一个Term的Leader未Committed的Log Entry。这部分Log Entry需要转变为Committed,即通过Noop。
Leader为每个Follower维护一个nextId,标示下一个要发送的logIndex。Leader通过回溯寻找Follower上最后一个CommittedId,然后Leader发送其后的LogEntry。
重新选取Leader之后,新的Leader没有之前内存中维护的nextId,以本地lastLogIndex+1作为每个节点的nextId。这样根据节点的AppendEntries应答可以调整nextId:
local.nextIndex = max(min(local.nextIndex-1, resp.LastLogIndex+1), 1)
Log Compaction
在实际系统中,Log会无限制增长,导致Log占用太多的磁盘空间,需要更长的启动时间来加载,将会导致系统不可用。需要对日志做压缩。
Snapshot是Log Compaction的常用方法,将系统的全部状态写入一个Snapshot中,并持久化的一个可靠存储系统中,完成Snapshot之后这个点之前的Log就可以被删除了。
- Leader、Follower独立的创建快照。
- Follower与Leader差距过大,则InstallSnapshot,Leader chunk发送Snapshot给Follower。
- Snapshot中的数据一定是Applied,那么肯定是Committed的
- Log达到一定大小、数量、超过一定时间可以做Snapshot。
- 如果底层存储支持COW,则可以使用COW做Snapshot,减小对Log Append的影响。
Membership Change
可以参考Raft Paper:https://raft.github.io/raft.pdf
当Raft集群进行节点变更时,新加入的节点可能会因为需要花费很长时间同步Log而降低集群的可用性,导致集群无法commit新的请求。
假设原来集群又3个节点,可以容忍3 - (3/2+1) = 11个节点出错,这时由于机器维修、增加副本解决热点读等原因又新加入了一个节点,这时也是可以容忍4 - (4/2+1) = 11个节点出错,恰好原来的一个节点出错了,此时虽然可以commit但是得等到新的节点完全追上Leader的日志才可以,而新节点追上Leader日志花费的时间比较长,在这期间就没法commit,会降低系统的可用性。
为了避免这个问题,引入了节点的Learner状态,当集群成员变更时,新加入的节点为Learner状态,Learner状态的节点不算在Quorum节点内,不能参与投票;只有Leader确定这个Learner节点接收完了Snapshot,可以正常同步Log了,才可能将其变成可以正常的节点。
Safety
- Election Safety:一个Term下最多只有一个Leader。
- Leader Append-Only:Leader不会覆盖或者是删除自己的Entry,只会进行Append。
- Log Matching:如果两个Log拥有相同的Term和Index,那么给定Index之前的LogEntry都是相同的。
- Leader Completeness:如果一条LogEntry在某个Term下被Commit了,那么这条LogEntry必然存在于后面Term的Leader中。
- State Machine Safety:如果一个节点已经Apply了一条LogEntry到状态机,那么其他节点不会向状态机中Apply相同Index下的不同的LogEntry。
功能完善
Pre-Vote
Pre-Vote主要避免了网络分区节点加入集群时,引起集群中断服务的问题。
Follower在转变为Candidate之前,先与集群节点通信,获得集群Leader是否存活的信息,如果当前集群有Leader存活,Follower就不会转变为Candidate,也不会增加Term,就不会引起Leader StepDown,从而不会导致集群选主中断服务。
Transfer Leader
Transfer Leader可以把当前Raft Group中的Leader转换给另一个Follower,可用于负载均衡、重启机器等。
在进行transfer leadership时,先block当前Leader的写入,然后使Transferee节点日志达到Leader的最新状态,进而发送TimeoutNow请求,触发Transferee节点立即选主。
但是不能无限制的block Leader的写入,会影响线上服务。通常可以为transfer leadership设置一个超时时间,超时之后如果发现Transferee节点Term没有发生变化,说明Transferee节点没有追上数据,没有选主成功,transfer leadership就失败了。
Network Partition
网络分区主要包含对称网络分区(Symmetric network partitioning)和非对称网络分区(Asymmetric network partitioning)。
Symmetric network partitioning
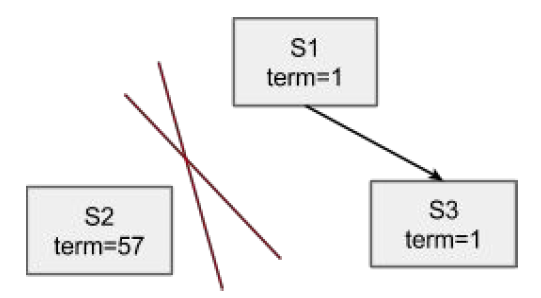
S1为当前Leader,网络分区造成S2和S1、S3心跳中断,S2既不会被选成Leader,也不会收到Leader的消息,而是会一直不断地发起选举。Term会不断增大。为了避免网络恢复后,S2发起选举导致正在工作的Leader step-down,从而导致整个集群重新发起选举,可以使用pre-vote来阻止对称网络分区节点在重新加入时,会中断集群的问题。因为发生对称网络分区后的节点,pre-vote不会成功,也就不会导致集群一段时间内无法正常提供服务的问题。
Asymmetric network partitioning
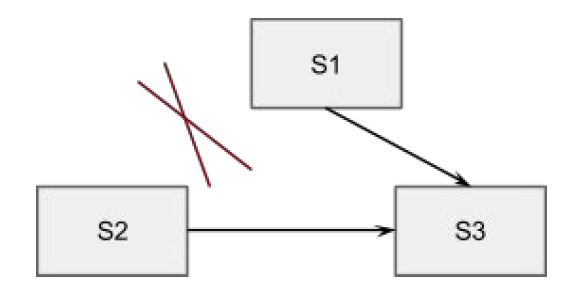
S1、S2、S3分别位于三个IDC,其中S1和S2之间网络不通,其他之间可以联通。这样一旦S1或者是S2抢到了Leader,另外一方在超时之后就会触发选主,例如S1为Leader,S2不断超时触发选主,S3提升Term打断当前Lease,从而拒绝Leader的更新。
可以增加一个trick的检查,每个Follower维护一个时间戳记录收到Leader上数据更新的时间,只有超过ElectionTimeout之后才允许接受Vote请求。这个类似Zookeeper中只有Candidate才能发起和接受投票,就可以保证S1和S3能够一直维持稳定的quorum集合,S2不能选主成功。
SetPeer
Raft只能在多数节点存活的情况下才可以正常工作,在实际环境中可能会存在多数节点故障只存活一个节点的情况,这个时候需要提供服务并修复数据。因为已经不能达到多数,不能写入数据,也不能做正常的节点变更。Raft库需要提供一个SetPeer的接口,设置每个节点的复制组节点列表,便于故障恢复。
假设只有一个节点S1存活的情况下,SetPeer设置节点列表为{S1},这样形成一个只有S1的节点列表,让S1继续提供读写服务,后续再调度其他节点进行AddPeer。通过强制修改节点列表,可以实现最大可用模式。
Noop
在分布式系统中,对于一个请求都有三种返回结果:成功、失败、超时。
在failover时,新的Leader由于没有持久化commitIndex,所以并不清楚当前日志的commitIndex在哪,也即不清楚log entry是committed还是uncommitted状态。通常在成为新Leader时提交一条空的log entry来提交之前所有的entry。
RAFT中增加了一个约束:对于之前Term的未Committed数据,修复到多数节点,且在新的Term下至少有一条新的Log Entry被复制或修复到多数节点之后,才能认为之前未Committed的Log Entry转为Committed。即最大化commit原则:Leader在当选后立即追加一条Noop并同步到多数节点,实现之前Term uncommitted的entry隐式commit。
- 保证commit的数据不会丢。
- 保证不会读到uncommitted的数据。
可参考知乎幽灵复现问题:关于Paxos “幽灵复现”问题看法
MultiRaft
元数据相比数据来说整体数据量要小的多,通常单台机器就可以存储。我们也通常借助于Etcd等使用单个Raft Group来进行元数据的复制和管理。但是单个Raft Group,存在以下两点弊端:
- 集群的存储容量受限于单机存储容量(排除使用分布式存储)。
- 集群的性能受限于单机性能(读写都由Leader处理)。
对于集群元数据来说使用单个Raft Group是够了,但是如果想让Raft用于数据的复制,那么必须得使用MultiRaft,也即有多个复制组,类似于Ceph的PG,每个PG、Raft Group是一个复制组。
但是Raft Group的每个副本间都会建立链接来保持心跳,如果多个Raft Group里的副本都建立链接的话,那么物理节点上的链接数就太多了,需要复用物理节点的链接。如下图cockroachdb multi raft所示:

MultiRaft还需要解决以下问题:
- 负载均衡:可以通过Transfer Leadership的功能保持每个物理节点上Leader个数大致相当。
- 链接复用:一个物理节点上的所有Raft Group复用链接。会有心跳合并、Lease共用等。
- 中心节点:用来管理集群包括MultiRaft,使用单个Raft Group做高可靠,类似Ceph Mon。
性能优化
Batch
- Batch写入落盘:对每一条Log Entry都进行fsync刷盘效率会比较低,可以在内存中缓存多个Log Entry Batch写入磁盘,提高吞吐量,类似于Ceph FileStore批量的写Journal。
- Batch网络发送:Leader也可以一次性收集多个Log Entry,批量的发送给Follower。
- Batch Apply:批量的Apply已经commit的Log到业务状态机。
Batch并不会对请求做延迟来达到批量处理的目的,对单个请求的延迟没有影响。
PipeLine
Raft依赖Leader来保持集群的数据一致性,数据的复制都是从Leader到Follower。一个简单的写入流程如下,性能是完全不行的:
- Leader收到Client请求。
- Leader将数据Append到自己的Log。
- Leader将数据发送给其他的Follower。
- Leader等待Follower ACK,大多数节点提交了Log,则Apply。
- Leader返回Client结果。
- 重复步骤1。
Leader跟其他节点之间的Log同步是串行Batch的方式,如果单纯使用Batch,每个Batch发送之后Leader依旧需要等待该Batch同步完成之后才能继续发送下一个Batch,这样会导致较长的延迟。可以通过Leader跟其他节点之间的PipeLine复制来改进,会有效降低延迟。
Parallel
顺序提交
将Leader Append持久化日志和向Followers发送日志并行处理。Leader只需要在内存中保存未Committed的Log Entry,在多数节点已经应答的情况下,无需等待Leader本地IO完成,直接将内存中的Log Entry直接Apply给状态机即可。
乱序提交
Out-of-Order参考:PolarFS: ParallelRaft、BlueStore源码分析之事物状态机:IO保序
乱序提交要满足以下两点:
- Log Entry之间不存在覆盖写,则可以乱序Commit、Apply。
- Log Entry之间存在覆盖写,不可以乱序,只能顺序Commit、Apply。
上层不同的应用场景限制了提交的方式:
- 对IO保序要求比较严格,那么只能使用顺序提交。
- 对IO保序没有要求,可以IO乱序完成,那么可顺序提交、乱序提交都可以使用。
不同的分布式存储需要的提交方式:
- 分布式数据库(乱序提交):其上层可串行化的事物就可以保证数据一致性,可以容忍底层IO乱序完成的情况。
- 分布式KV存储(乱序提交):多个KV之间(排除上层应用语义)本身并无相关性,也不需要IO保序,可以容忍IO乱序。
- 分布式对象存储(乱序提交):本来就不保证同一对象的并发写入一致性,那么底层也就没必要顺序接收顺序完成IO,天然容忍IO乱序。
- 分布式块存储(顺序提交):由于在块存储上可以构建不同的应用,而不同的应用对IO保序要求也不一样,所以为了通用性只能顺序提交。
- 分布式文件存储(顺序提交):由于可以基于文件存储(Posix等接口)构建不同的应用,而不同的应用对IO保序要求也不一样,所以为了通用性只能顺序提交,当然特定场景下可以乱序提交,比如PolarFS适用于数据库。
- 分布式存储:具体能否乱序提交最终依赖于应用语义能否容忍存储IO乱序完成。
简单分析
单个Raft Group只能顺序提交日志,多个Raft Group之间虽然可以做到并行提交日志,但是受限于上层应用(数据库等)的跨Group分布式事物,可能导致其他不相关的分布式事物不能并行提交,只能顺序提交。
上层应用比如数据库的分布式事物是跨Group(A、B、C)的,Group A被阻塞了,分布式事物不能提交, 那么所有的参数者Group(B、C)就不能解锁,进而不能提交其他不相关的分布式事物,从而引发多个Group的链式反应。
Raft不适用于多连接的高并发环境中,Leader和Follower维持多条连接的情况在生产环境也很常见,单条连接是有序的,多条连接并不能保证有序,有可能发送次序靠后的Log Entry先于发送次序靠前的Log Entry达到Follower,但是Raft规定Follower必须按次序接受Log Entry,就意味着即使发送次序靠后的Log Entry已经写入磁盘了(实际上不能落盘得等之前的Log Entry达到)也必须等到前面所有缺失的Log Entry达到后才能返回。如果这些Log Entry是业务逻辑顺序无关的,那么等待之前未到达的Log Entry将会增加整体的延迟。
其实Raft的日志复制和Ceph基于PG Log的复制一样,都是顺序提交的,虽然可以通过Batch、PipeLine优化,但是在并发量大的情况下延迟和吞吐量仍然上不去。
具体Raft乱序提交的实现可参考:PolarFS: ParallelRaft
Asynchronous
我们知道被committed的日志肯定是可以被Apply的,在什么时候Apply都不会影响数据的一致性。所以在Log Entry被committed之后,可以异步的去Apply到业务状态机,这样就可以并行的Append Log和Apply Log了,提升系统的吞吐量。
其实就和Ceph BlueStore的kv_sync_thread和kv_finalize_thread一样,每个线程都有其队列。kv_sync_thread去写入元数据到RocksDB(请求到此已经成功),kv_finalize_thread去异步的回调上层应用通知请求成功。
ReadIndex
Raft的写入流程时走一遍Raft,保证了数据的一致性。为了实现线性一致性读,读流程也可以走一遍Raft,但是会产生磁盘IO,性能不好。Leader具有最新的数据,理论上Leader可以读取到最新的数据。但是在网络分区的情况下,无法确定当前的Leader是不是真的Leader,有可能当前Leader与其他节点发生了网络分区,其他节点形成了一个Group选举了新的Leader并更新了一些数据,此时如果Client还从老的Leader读取数据,便会产生Stale Read。
读流程走一遍Raft、ReadIndex、Lease Read都是用来实现线性一致性读,避免Stale Read。
- 当收到读请求时,Leader先检查自己是否在当前Term commit过entry,没有否则直接返回。
- 然后Leader将自己当前的commitIndex记录到变量ReadIndex里面。
- 向Follower发起Heartbeat,收到大多数ACK说明自己还是Leader。
- Leader等待 applyIndex >= ReadIndex,就可以提供线性一致性读。
- 返回给状态机,执行读操作返回结果给Client。
线性一致性读:在T1时刻写入的值,在T1时刻之后读肯定可以读到。也即读的数据必须是读开始之后的某个值,不能是读开始之前的某个值。不要求返回最新的值,返回时间大于读开始的值就可以。
注意:在新Leader刚刚选举出来Noop的Entry还没有提交成功之前,是不能够处理读请求的,可以处理写请求。也即需要步骤1来防止Stale Read。
原因:在新Leader刚刚选举出来Noop的Entry还没有提交成功之前,这时候的commitIndex并不能够保证是当前整个系统最新的commitIndex。考虑这个情况:w1->w2->w3->noop| commitIndex在w1;w2、w3对w1有更新;应该读的值是w3因为commitIndex之后可能还有Log Entry对该值更新,只要w1Apply到业务状态机就可以满足applyIndex >= ReadIndex,此时就可以返回w1的值,但是此时w2、w3还未Apply到业务状态机,就没法返回w3,就会产生Stale Read。必须等到Noop执行完才可以执行读,才可以避免Stale Read。
Follower Read
如果是热点数据么可以通过提供Follower Read来减轻Leader的读压力,可用非常方便的通过ReadIndex实现。
- Follower向Leader请求ReadIndex。
- Leader执行完
ReadIndex章节的前4步(用来确定Leader是真正的Leader)。 - Leader返回commitIndex给Follower作为ReadIndex。
- Follower等待 applyIndex >= ReadIndex,就可以提供线性一致性读。
- 返回给状态机,执行读操作返回结果给Client。
Lease Read
Lease Read相比ReadIndex更近了一步,不仅省去了Log的磁盘开销,还省去了Heartbeat的网络开销,提升读的性能。
基本思路:Leader获取一个比election timeout小的租期(Lease),因为Follower至少在election timeout时间之后才会发送选举,那么在Lease内是不会进行Leader选举,就可以跳过ReadIndex心跳的环节,直接从Leader上读取。但是Lease Read的正确性是和时间挂钩的,如果时钟漂移比较严重,那么Lease Read就会产生问题。
- Leader定时发送(心跳超时时间)Heartbeat给Follower, 并记录时间点start。
- 如果大多数回应,那么新的Lease到期时间为
start + Lease(<election timeout)。 - Leader确认自己是Leader后,等待applyIndex >= ReadIndex,就可以提供线性一致性读。
- 返回给状态机,执行读操作返回结果给Client。
Double Write-Store
我们知道Raft把数据Append到自己的Log的同时发送请求给Follower,多数回复ACK就认为commit,就可以Apply到业务状态机了。如果业务状态机(分布式KV、分布式对象存储等)也把数据持久化存储,那么数据便Double Write-Store,集群中存在两份相同的数据,如果是三副本,那么就会有6份。
接下来主要思考元数据、数据做的一点点优化。
通常的一个优化方式就是先把数据写入Journal(环形队列、大小固定、空间连续、使用3D XPoint、NVME),然后再把数据写入内存即可返回,最后异步的把数据刷入HDD(最好带有NVME缓存)。
元数据
元数据通常使用分布式KV存储,数据量比较小,Double Write-Store影响不是很大,即使存储两份也不会浪费太多空间,而且以下改进也相比数据方面的改进更容易实现。
可以撸一个简单的Append-Only的单机存储引擎WAL来替代RocksDB作为Raft Log的存储引擎,Apply业务状态机层的存储引擎可以使用RocksDB,但是可以关闭RocksDB的WAL,因为数据已经存储在Append-Only的Raft Log了,细节仍需考虑。
数据
这里的数据通常指非结构化数据:图片、文档、音视频等。非结构化数据通常使用分布式对象存储、块存储、文件存储等来存储,由于数据量比较大,Double Store是不可接受的,大致有两种思路去优化:
- Raft Log、User Data分开存:Raft Log只存op-cmd,不存data,类似于Ceph的PG Log。
- Raft Log、User Data一起存:作为同一份数据来存储。Bitcask模型天然Append更容易实现。
参考资源
转载请注明:史明亚的博客 » 浅谈分布式存储之raft




