
前言
学习一个开源项目应该先从其架构设计入手,尤其是存储类的开源项目,在了解其整体设计之后,应该沿着IO路径去阅读代码,再由表及里去分析每个模块的具体功能。
目录
架构设计
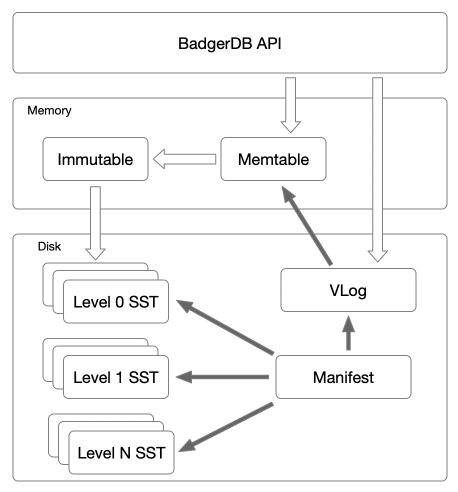
BadgerDB是基于Wisckey论文实现的,而Wisckey论文新颖的地方便在于把LevelDB和RocksDB做key-value分离,所以大体架构遵循LevelDB,区别就在于去掉了LSM-Tree里面的WAL,用VLog代替。在实现上,去掉了current文件。架构图如下所示:
功能特性
- 支持常用的Get、Put、Delete、Batch等操作。
- 实现了SSI隔离的Transaction,支持读、写事物。
- 所有的操作都是以Transaction执行的。
- 支持MVCC,支持多版本的key-value。
- 支持对key设置TTL以及UserMeta。
- 所有的key都是有序存储的,支持Iteration和Prefix-Scan。
- 支持key的Compaction以及value的GC。
写流程
在这里只会给出基本的写流程,涉及MVCC、Transaction等更详细的写流程会在后续章节分析。
- 把key-vlaue整体append写Vlog。
- 如果value size大于LSM-Tree阈值,则写key-value偏移位置到memtable。
- 否则写key-value本身到memtable,memtable是一个内存skiplist。
- 当memtable size超过一定限制后,将memtable转换为immutable。
- 后台会启动一个goroutine专门flush immutable到level0的sstable。
- 后台也会启动N个goroutine来做不同level之间的compaction。
大多数情况下,写入流程进行到步骤1和步骤2就已经结束了。但是当数据量比较大的时候,内存中的memtable达到了设置的最大数,就会阻塞后续的写,直到内存中的memtable小于设置的阈值,此时写入的性能就会下降。
读流程
同时在这里只会给出基本的读流程,涉及MVCC、Transaction等更详细的读流程会在后续章节分析。
- 从memtable中查找key,如果存在则取出,当value在LSM-Tree里时直接返回,在VLog中时,根据value的偏移位置从VLog里面读出数据返回。
- 如果不存在,则从immutable里面查找key,如果找到,则按照步骤1的操作返回即可,如果找不到执行步骤3。
- 如果在内存的memtable和immutable都没有找到,就需要从磁盘里面的sstable里找了。
- 和LevelDB一样,level0的数据是最新的,level1-leveln依次次之。则会按照level层级,依次找每层的文件,找到了就返回,找不到就返回失败。
VLog
在这里只会简单介绍VLog,关于VLog的具体分析会在后续文章给出。
为了做GC,VLog也会存储key,此时VLog里面便拥有完整的数据了。而LSM-Tree通常也会先写WAL,此时可以使用VLog来替代WAL,减少一次写放大。后续的恢复也是根据VLog来进行数据恢复。
Manifest
存放在LSM-Tree里面的不同level的数据会做Compaction,此时会涉及到sstable的创建与删除。同时故障随时都会发生,如果再做Compaction时,新版本的sstable已经创建并且合并完了,在删除老版本的sstable时宕机了,此时老版本的sstable便会成了垃圾数据,所以需要对sstable进行版本控制,便是Manifest文件的作用。凡是涉及到sstable文件的操作都需要在Manifest文件中记录。
- Manifest以日志的形式append写入。
- 所有对sstable的操作都会append写入到Manifest文件。
- Manifest文件记录了每一个层级有哪些sstable,每个sstable的key范围、删除数据量等重要的元数据。
- LevelDB会有多个Manifest和current文件,BadgerDB只有两个Manifest文件(一个mutable和一个immutable),没有current文件。
由于Manifest文件是append写入的,同时每次DB重启时也会根据该文件来恢复sstable的信息,所以会根据一定的策略对Manifest文件做Snapshot以及切割(Rewrite),来防止Manifest文件无限的增长和减少恢复的时间。
转载请注明:史明亚的博客 » BadgerDB源码分析之架构设计




