
前言
LSM-Tree的优势在于将随机写转换为顺序写,将大块的内存连续的写入到磁盘,减少磁盘Seek(磁头移动)的时间,同时又是按照key有序组织的,查找起来也比较快,但同时也带来了写放大和读放大。这些优化很适用于HDD,但是对SSD是极其不友好的,所以Wisckey提出了一种面向SSD的,将key-value分离存储的方法。BadgerDB便是基于该论文实现的。
目录
LSM读写放大
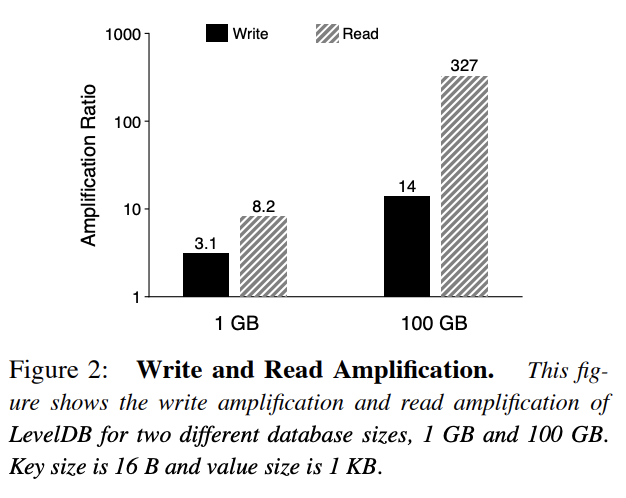
LSM写放大主要是因为Compaction,每次在两层之间做Compaction时,都需要将多个sstable读出来做排序(读放大),再写到磁盘。
LSM读放大LSM查找一个key时,经过的流程是memtable—>imutable—>level’s sstable。此时假设该key不存在,memtable和imutable是内存操作很快,但是在sstabe这一层,就需要把每一层做二分查找搜一遍。特别是第0层是全局无序的,有overlap存在,需要查找每一个文件,虽然有bloom filter但是依旧影响查找的效率。
value比较大的时候Compaction的问题尤其明显,期间sstable的读写都是将key-value一起进行的,value过大时效率便会很低。这些放大的影响在HDD上抵消磁盘的Seek消耗还是值得的。但是SSD就不一样了,SSD随机读写要快的多,并且可以使用其并行随机读取的特性。LSM适用于小value的场景,在对象场景中不适用,因此就需要把key-value分离存储来适应更多的场景。
Wisckey设计目标
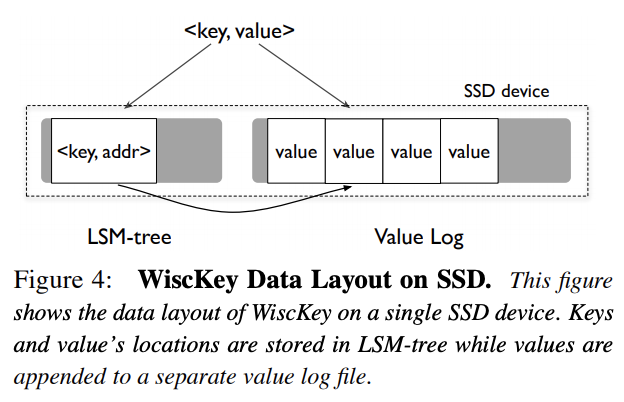
Wisckey的基本原理:将key-value分离存储。LSM-Tree里面存储的是一个key以及value的偏移位置,value本身以WAL方式append写入到log文件中。这样在做Compaction的时候就只需要重写key以及value的偏移位置就可以了,在key-szie远远小于value-size的场景中降低写放大的效果显著。
然而当value很小的时候,重写value的开销就很小,key-value分离带来的好处便不足以抵消其本身的开销(读写key-value需要操作不同的文件,在range query的场景下,会产生多次的随机IO)
写流程先把value append写入vlog(为了GC操作也会写入key),然后把key-value偏移位置写入LSM-Tree。
读流程先从LSM-Tree里面读取key-value偏移位置,然后从vlog读取value。
删流程只需把key从LSM-Tree里面删除,无需操作vlog。
由于做Compaction时不需要重写value,大大减小了写放大。同时LSM-Tree更小,一个Block能存储更多的key,也会相应的减小读放大,能缓存到的key-value偏移位置也更多,缓存效果会更好。总体来看,Wisckey很像是一个用LSM-Tree做索引用的BitCask。
并行Range查询
Range-Query允许用户查询一段有序range的kv对,可以对其进行遍历。当发起一起Range-Query的时候,最终会被转换为vlog的多次随机读。相比于LSM-Tree的顺序读,value小的情况反而增加了延迟。因此在这种场景下,Wisckey会通过多个后台线程对后面的多个数据进行预读并缓存,充分利用SSD内部的并行性。预读缓存对于大范围的range-query效果比较明显,但是对于小范围的range-query可能作用不大。根据论文的实验数据,当value大于4KB时,读的性能才体验出来。
Crash一致性
思考第一个问题:既然也会写入key到vlog里面,那么还需要LSM-Tree的WAL吗?
Wisckey的做法是去掉了LSM-Tree的WAL,直接使用vlog来代替,因为vlog里面存储了完整的key-value数据。更细的写入流程是:
- 把key-value都全部append写入vlog。
- 把key-value偏移位置写入LSM-Tree的memtable。
- LSM-Tree会按照一定策略把memtable做Minor-Compaction写入sstable。
思考另一个问题:key-value分离存储后如何保证key-value写入的一致性?
因为Wisckey是先写入vlog,再写入LSM-Tree,所以会有以下几种失败情况:
vlog写入失败,LSM-Tree肯定写入失败:可能会残留部分vlog数据,会有GC机制来回收。vlog写入成功,LSM-Tree写入失败:此时vlog的值便成了垃圾数据,会有GC机制来回收。vlog写入成功,LSM-Tree写入成功后立刻崩溃:因为已经移除了LSM-Tree的WAL,所以写入LSM-Tree也仅仅是写入了内存的memtable,此时程序或者机器发生崩溃LSM-Tree的数据依旧会丢失。Wisckey的做法是保存一个key-value对<head, head-vLog-offset>在LSM-Tree中。每次Open数据库的时候,读取head的值,然后依次读取head-vLog-offset之后的记录,并将key-value偏移位置写入到LSM-Tree,最后更新head的值。如果更新head的值发生崩溃也无所谓,只不过再次Open数据库的时候多重放一点记录罢了。
GC机制
由于删除操作只会删除LSM-Tree里面的key-value偏移位置,不会删除vlog的value,同时在Crash一致性章节提出的各种Crash Case也都需要GC机制来做垃圾数据清理。
Wisckey除了会存储<head, head-vLog-offset>外,还会存储<tail, tail-vLog-offset>,用来标识最后做GC的位置。会从tail开始扫描vlog,获取key-value。为了不影响在线服务,会每次取出vlog最旧的一部分数据(几MB),通过读取LSM-Tree来验证其有效性,如果过期或者被删除则丢弃;有效则append写入到最新的vlog,然后更新tail的值,并删除tail之前的数据,通过 fallocate()释放无效的文件磁盘空间。
改进点
Wisckey key-value分离在大value下效果显著,但是对于小value却不甚友好,不如LSM-Tree。为此我们可以设置一个value阈值,当超过阈值时value存入vlog,小于阈值时存入LSM-Tree,提高小value场景的性能,BadgerDB正是这么做的。
参考资源
转载请注明:史明亚的博客 » BadgerDB源码分析之Wisckey论文




