
前言
分布式系统区别于单机系统是在于能够将数据分布到多个节点,并且在多个节点之间实现负载均衡。所以分布式系统面临两个问题:一是如何将海量数据分散到多个节点;二是多个节点之间如何实现负载均衡。无论是KV存储、对象存储、块存储、文件存储还是数据库,所有的分布式存储在数据分布方面都面临相同的问题,本文将试着分析数据分布以及负载均衡可选的方案并权衡其利弊。
目录
衡量指标
我们假设数据分布的目标数据是以key标识的value即k-v数据,数据分布算法有两个基本的指标:
- 稳定性:每次
key通过数据分布算法得到的分布结果应保持基本稳定。 - 均匀性:不同存储节点之间的负载应保持均衡(容量均衡、IO均衡)。
而这两个指标在一定程度上是相互矛盾的。当有存储节点增加或者删除时,为了保持稳定,应该尽量少的进行数据迁移和重新分布;但是为了保持均匀,就会导致较多的数据迁移和重新分布。所以我们希望在这两个极端情况下,找到一个点来获得合适的稳定性和均匀性。
同时在工程实现上,我们还要从以下几方面来衡量分布算法的优劣性:
- 性能扩展性:数据分布算法不应该随着系统规模扩大而显著的增加运行时间。
- 节点异构性:不同存储节点(HDD、SSD、NVME)的性能和容量有很大差异,好的数据分布算法应该考虑节点的异构,提供加权的数据均匀方式。
- 故障域隔离:为了数据可靠性,数据一般都是冗余存储的,数据分布算法应该隔离冗余副本的故障域(不同机房、不同机架、不同机器等)。
分布算法
数据分布算法主要有两种:Hash分布、Range分布。Hash分布代表系统有Amazon的DynamoDB、Redhat的Ceph;Range分布就是按照顺序分布,所有的k-v都是有序的,整体上来看是一张有序的大表,代表系统有Google的Bigtable、PingCAP的TIDB。
Hash分布
Hash分布不用保存元数据,每次直接计算就行。常用的有简单Hash、二次Hash、一致性Hash、分片Hash,在这里,我们不会讨论具体的Hash函数以及一致性Hash的详细原理,具体知识Google一大堆。我们会着重分析每种Hash在节点增加或删除时带来的数据迁移量以及最优解。
简单Hash
最简单的Hash算法便是直接对key做Hash,然后对节点数取模,因此选取一个散列性好的Hash函数是至关重要的。但是当有节点增加或者删除的时候,带来的数据迁移是灾难性的。
我们在数据是海量的,分布是均匀的(很重要),即对任意一个数值取模都是均匀的的假设前提下,以增加节点为例,探讨一下增加的节点数和原有节点数的比例关系的不同是怎样影响迁移的数据量的。
我们定义以下术语:
v:key的Hash值x:原有节点数y:新增节点数z:最终节点数m:x和z的最小公倍数
结论:总体迁移数据量为(m-x)/m,只有当z是x和z的最小公倍数m时,也就是z=m ---> z=2*x ---> y=x新增节点数等于原有节点数的情况下,总体迁移的数据量最小(一半数据量),其余情况迁移数据量均大于一半的量。
原因:只有当v % m < x时数据才不会迁移,又因为我们假设数据是分布均匀的,所以我们可以把数据集合收敛到[0, m],因为[0, x)的数据集合不会迁移,所以迁移的数据集合便为[x, m],所以迁移的数据量为(m-x)/m。
示例:

StableHash
StableHash有两个特点:一是需要进行两次Hash取模;二是取模的基数并不一定是节点个数。在这里我们引用Ceph的stable_mod函数:
/*
* stable_mod func is used to control number of placement groups.
* similar to straight-up modulo, but produces a stable mapping as b
* increases over time. b is the number of bins, and bmask is the
* containing power of 2 minus 1.
*
* b <= bmask and bmask=(2**n)-1
* e.g., b=12 -> bmask=15, b=123 -> bmask=127
*/
static inline int ceph_stable_mod(int x, int b, int bmask)
{
if ((x & bmask) < b)
return x & bmask;
else
return x & (bmask >> 1);
}
- x:输入集合的数据。
- b:取模的基数。
- bmask:取模基数的掩码,总是2的幂次方。
实际上取模的基数正是bmask,利用了位运算,加快取模速度。举例:如果b是12,那么取模的基数bmask是15,如果得到的模是13的话,那么便超出了12的范围,便会把bmask 15向右移一位为7,对7再次取模。
这样做的好处是可以控制迁移的量,增加节点数和原有节点数相同的情况下,迁移的数据量还是一半。但是增加节点数小于原有节点数的时候,迁移的数据就不像简单Hash那样大规模迁移了,而是仅仅迁移y/2x的数据量。
一致性Hash
一致性Hash的优点在于加入或者删除节点时只会影响到相邻节点,对其他节点没有影响;而且考虑了一部分节点异构性,可以设置不同节点不同的虚拟节点数。在这里我们只讨论带有虚拟节点的一致性Hash。我们在数据是海量的,分布是均匀的;虚拟节点散列也是均匀的这两个前提下,很容易得出加入或者删除一个节点数据迁移量是1/N,如果加入节点数和原来节点数相同,那么迁移的数据量也为一半。
分片Hash
分片将Hash环切分为相同大小的分片,然后将这些分片交给不同的节点负责。分片Hash定位数据需要两级操作,以Ceph-CRUSH为例:先通过Hash(stable_hash)定位数据在哪一个分片上(pg),然后再找到分片对应的节点信息(CRUSH)。
分片Hash和虚拟节点的一致性Hash有着本质的区别:分片的划分和分片的分配被解耦。当一个节点退出时,不需要把其负责的分片顺时针交给其后节点,可以更加灵活的将整个分片交给任意节点;通常分片也是数据迁移、故障恢复、副本复制的最小单位。
Range分布
Hash分布的弊端破坏了数据的连续性,只支持随机读取操作,不支持顺序扫描。Range分布从整体上来看是一张有序的大表,每个范围称为一个小表,可以高效的支持顺序Scan操作。在关系型数据库中通常存在顺序Scan(Table Scan、Index Scan等)的场景,而分布式关系型数据库的数据分布也只能使用Range分布。
Range元数据
一个Range的大小默认为64MB,如果要支持1PB的数据,那么需要1600万个Range。Range元数据大小设置为256B字节是比较合理的(3*12个字节用来保存3副本地址,剩下的220字节保存自己的Key)。1600万个Range所需要的空间为4GB,在各个节点间都复制的话开销太大,所以Range的元数据也必须是分布式的。
我们采用两级索引(第一级用来保存第二级的位置信息,第二级用来保存Range的位置信息)。通过两级索引,可以支持64MB/256B=256K, 256K * 256K = 64G个Range,每个Range大小为64MB,所以最大可支持64G * 64M = 4EB的数据空间。
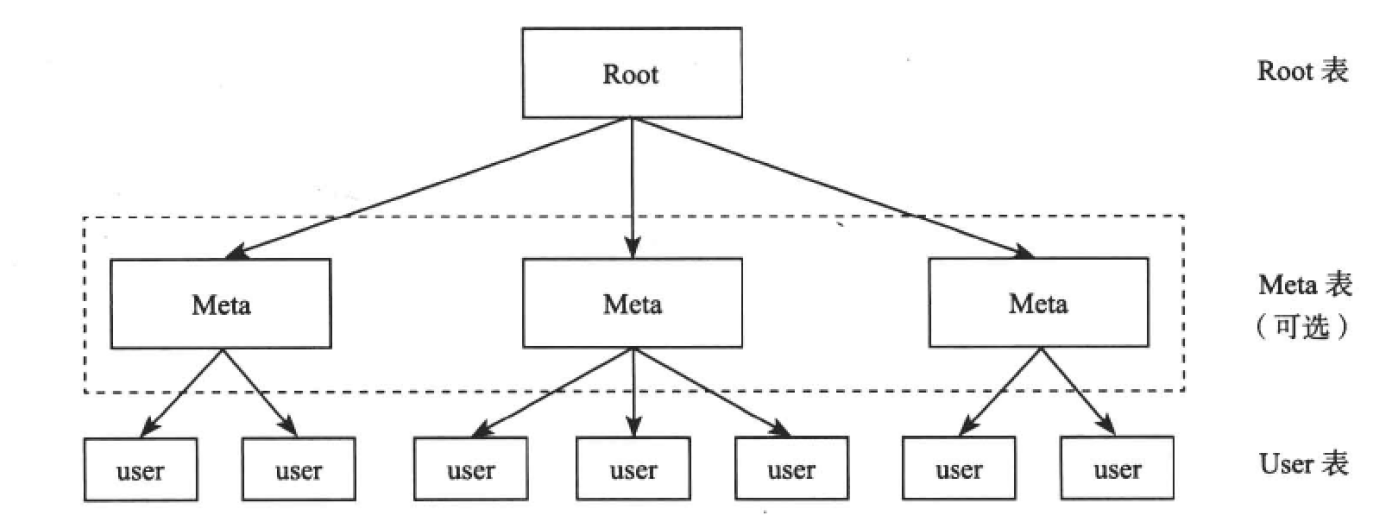
Root表为第一级索引的Range,Meta表为第二级索引的Range,User表为存储数据的Range。
读取User表时,先从Root表查找相应的Meta表所在的存储节点,然后通过Meta表查找相应的User表所在的存储节点。
Range分裂合并
随着数据的不断写入,某些子表可能变得很大,某些可能变得很小,数据分布很不均匀。这时候就要考虑子表的分裂与合并,将极大的增加系统的复杂度。
子表分裂:当一个子表太大超过一定阈值时需要分裂为两个子表,通过系统的负载均衡分布到多个节点。
子表合并:一般由数据删除引起,相邻的两个子表都很小时,可以合并为一个子表。
Range缺陷
- 初始并发度低:由于是有序的,每个子表刚开始只有一个Range,不能充分利用多个节点的并发性,随着数据的写入Range不断分裂,才可能充分利用多个节点。
- 单点顺序写入:在某个子表内一直顺序写入也不能利用多个节点的并发性,并发度接近1。但是这种场景一般都是写日志,可以采取相应的优化策略。
- 频繁读写小表:Range是最小的调度单元,如果一个Range不到容量阈值(64MB)而且读特别频繁,无论调度到哪个位置都会面临相同的问题,可以将小表放入缓存。
参考资源
转载请注明:史明亚的博客 » 浅谈分布式存储之数据分布




